
LREC-COLING 2024(The 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation)于2024年5月20日至25日在意大利都灵举行,我院师生撰写的题为《PLAES: Prompt-generalized and Level-aware Learning Framework for Cross-prompt Automated Essay Scoring》和《Zero-shot Cross-lingual Automated Essay Scoring》的2篇长文论文被录用,学生一作分别为陈源和何俊毅,第一作者为李霞教授。
LREC-COLING 2024是由欧洲语言资源协会(ELRA)和国际计算语言学委员会(ICCL)共同主办的自然语言处理领域国际顶级学术会议之一,是中国计算机学会(CCF)推荐的B类国际学术会议,会议于2024年5月20日至25日在意大利都灵举行。
论文1:Xia Li, Yuan Chen. PLAES: Prompt-generalized and Level-aware Learning Framework for Cross-prompt Automated Essay Scoring. COLING2024.
概述:以往的跨主题作文自动评分(AES)系统主要关注通过使用源主题和目标主题作文来获得共享知识。然而,这在实际情况下可能不可行,因为目标主题文章可能无法作为训练数据。当仅从源主题文章构建模型时,不同主题作文之间的显著差异可能会阻碍其推广到目标主题的能力。在这项研究中,提出了一种新的跨主题AES学习框架,以获取更多跨主题的通用知识,并提高模型区分写作水平的能力。为了在不同的主题下获得通用知识,通过元学习和所有源主题作文来训练第一阶段模型。为了提高模型区分写作水平的能力,我们提出了一种有等级感知的学习策略,该策略由一个主模型和三个低、中、高等级模型组成。然后,我们引入了一种对比学习策略,使主模型的作文表示更接近其相应的等级表示,远离其他两个等级表示,从而提高模型区分写作水平的能力,提高评分性能。在公共数据集上的实验结果说明了我们的方法的有效性。
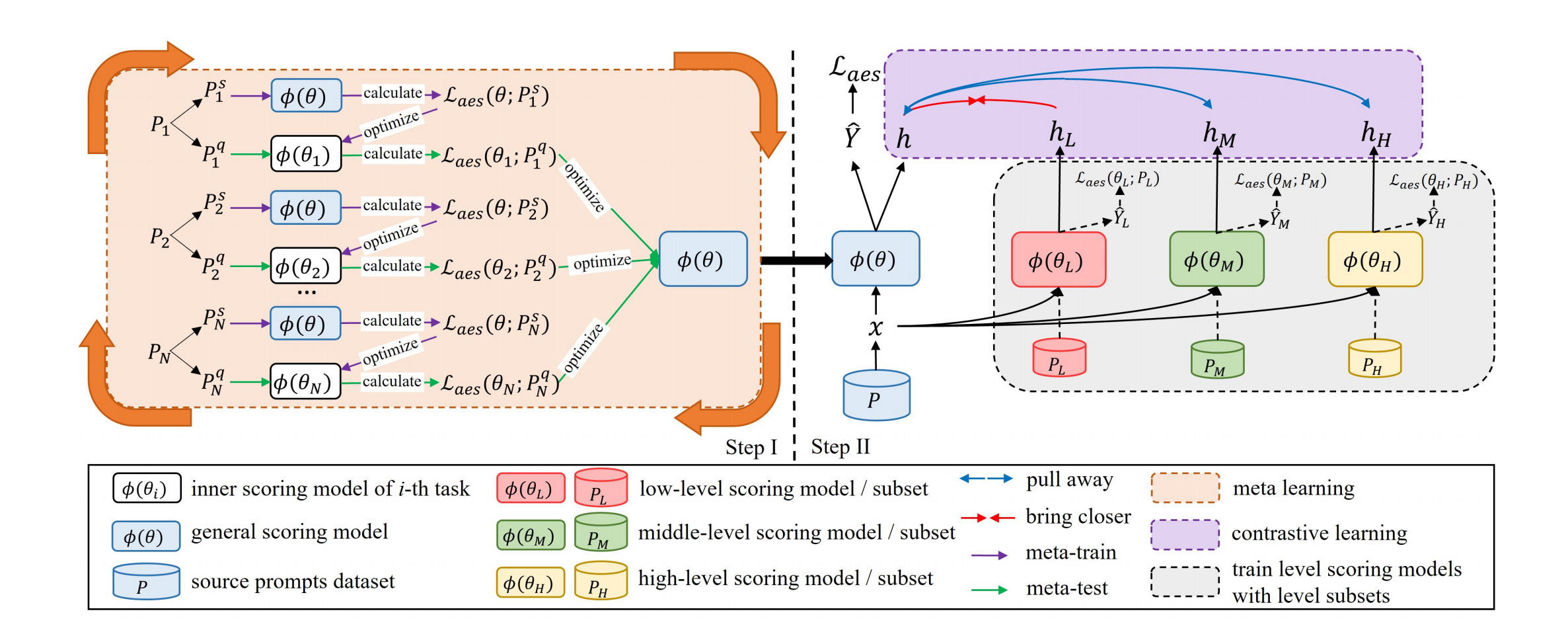
图1. 论文1模型图
论文2: Xia Li, Junyi He. Zero-shot Cross-lingual Automated Essay Scoring. COLING2024.
概述:由于创建高质量的多语言标注训练数据极具挑战性,资源短缺已成为自动作文评分(AES)领域的一个关键且棘手的问题。目前,鲜有研究聚焦并尝试解决此问题。本研究提出了一种创新的零样本跨语言评分方法,该方法基于预训练的多语言模型和写作质量对齐技术,能够对未知语言的作文进行评分。具体来说,我们利用多语言预训练模型作为作文编码器,深入全面地表示多语言文本。考虑到不同语言间写作质量评分的可比性,我们引入了一种创新的策略,实现了跨语言的作文质量对齐。此策略能够捕捉不同语言间的共享评分知识,从而提升模型对未知语言作文质量的识别能力。我们在包括捷克语、德语、英语、西班牙语、意大利语和葡萄牙语六种语言的数据集上开展了广泛实验,研究结果显示,我们的方法取得了最优的跨语言评分性能。
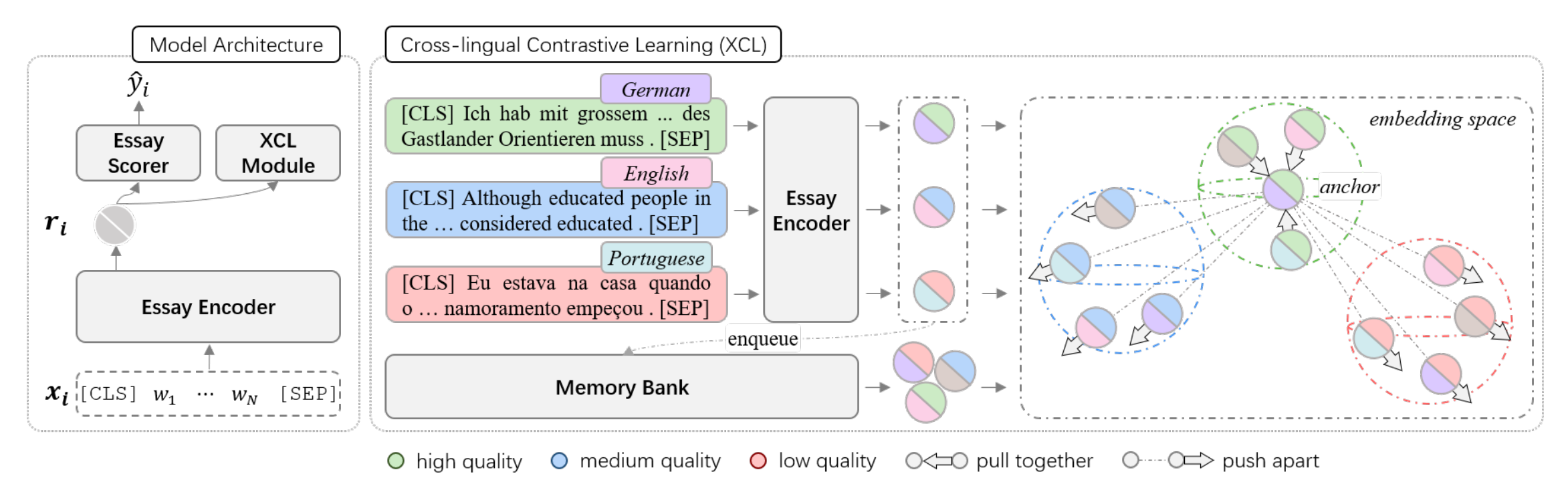
图2. 论文2模型图
初稿:陈源、何俊毅
审核:陈劲鸥
终审:李霞、王连喜





